
두 개의 도메인에 대해서 이미지를 변환할 수 있는 모델로, 이미지로 구성된 두가지 데이터 셋이 있을 때 한 데이터셋의 이미지들을 다른 데이터셋의 스타일로 변환
1. Introduction
"What if Monet had happened upon the little harbor in Cassis on a cool summer evening ?"
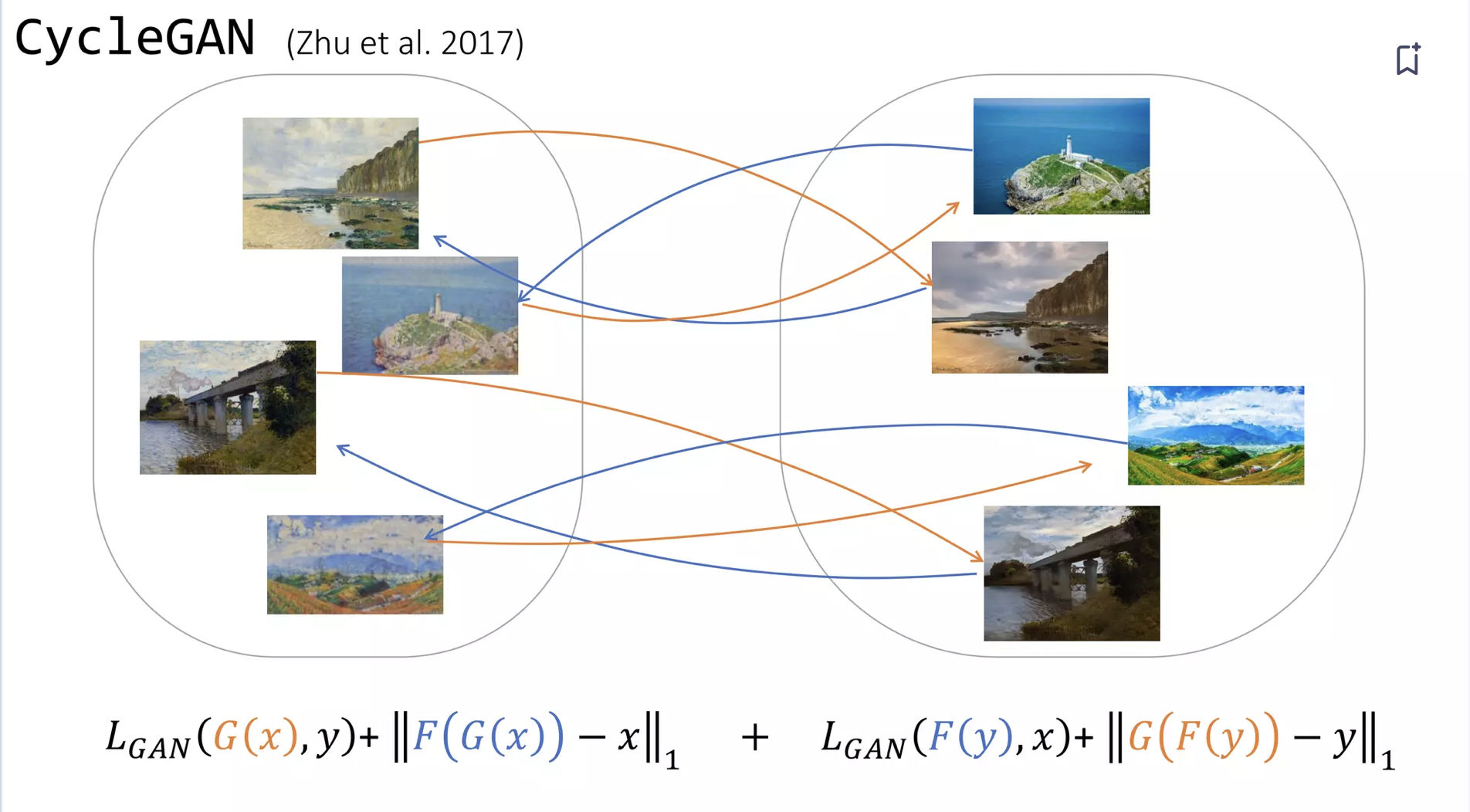
paired input-output 데이터없이 짝이 맞지 않는(unpaired) 데이터를 사용하여 두 이미지 도메인 간의 변환을 학습하는 방법을 찾아냄. 일반적으로 번역할 때 "cycle consistent(주기 일관성)" 있어야 한다는 속성을 이용하는데, 예를 들어 영어에서 프랑스어로 문장을 번역한 다음 프랑스어에서 영어로 번역을 다시 번역하면 원래 문장으로 돌아가야 한다.
우리에게 번역기 G: X → Y와 또 다른 번역기 F: Y → X가 있다면, G와 F는 서로 반전되어야 하고, 두 매핑은 모두 바이젝션이어야 한다.
매핑 G와 F를 동시에 훈련시키고 F(G(x) ≈ x와 G(y) ≈ y를 장려하는 주기 일관성 손실(Loss 1)을 추가함으로써 이미지가 한 도메인에서 다른 도메인으로 변환된 후 다시 원래 도메인으로 복원될 때 원본 이미지와의 차이를 최소화해 이미지의 핵심 구조와 내용이 보존되도록 함.
2. Related work
1. Generative Adversarial Networks (GANs): GANs는 이미지 생성, 이미지 편집, 표현 학습 등 다양한 분야에서 좋은 성능을 보여줌. GANs은 Adversarial Loss(적대적 손실 함수)를 사용하여 생성된 이미지가 실제 이미지와 구별할 수 없도록 만드는 아이디어에 기반. CycleGAN도 이러한 적대적 손실 개념을 사용하지만, 두 도메인 간의 변환을 학습하는 데 중점을 두고 있음.
- 생성자(Generator) 는 실제 데이터와 유사한 새로운 데이터를 생성하는 역할. 즉, 가짜 데이터를 만들어내는 역할
- 판별자(Discriminator) 는 입력받은 데이터가 실제 데이터인지 생성자가 만든 가짜 데이터인지를 판별하는 역할
적대적 손실 함수는 이 두 네트워크의 경쟁 관계를 수학적으로 모델링한 것.
판별자는 실제 데이터를 실제로, 가짜 데이터를 가짜로 정확하게 구분해내려고 학습하며, 이 과정에서 판별자의 손실을 최소화하는 방향으로 학습.
반면, 생성자는 판별자를 속여서 자신이 만든 가짜 데이터를 실제 데이터로 잘못 판별하게 만들려고 함. 생성자의 목표는 판별자가 가짜 데이터를 실제로 판별하도록 하는 것이며, 이 과정에서 생성자의 손실을 최대화하는 방향으로 학습.
2. Image-to-Image Translation: 이미지-이미지 변환은 하나의 이미지 표현을 다른 표현으로 변환하는 것을 목표로 함. 예를 들어, 흑백 이미지를 컬러 이미지로 변환하거나, 스케치를 사진으로 변환하는 작업 등이 이에 해당. "pix2pix" 프레임워크는 조건부 GAN을 사용하여 이러한 변환을 학습하지만, 짝을 이루는 학습 데이터가 필요하지만 CycleGAN은 이러한 제한을 극복하고, 짝이 없는 데이터로부터 변환을 학습함.
3. Unpaired Image-to-Image Translation: 짝이 없는 데이터로부터 이미지 변환을 학습하는 몇 가지 초기 시도 있었음. 예를 들어, CoGAN은 도메인 간 공유되는 표현을 학습하기 위해 가중치를 공유하는 두 개의 GAN을 사용했지만 품질의 제한이 있음. CycleGAN은 cycle consistency loss를 도입하여 이러한 한계를 극복함.
4. Cycle Consistency: 다른 분야에서도 구조적 데이터의 일관성을 유지하기 위한 방법으로 cycle consistency가 사용되었음. CycleGAN은 이미지 변환 문제에 cycle consistency를 적용하여, 변환된 이미지가 원본 도메인으로 다시 변환될 때 원본 이미지와 유사하도록 만들어줌
5. Neural Style Transfer: 스타일 전송은 콘텐츠 이미지와 스타일 이미지를 결합하여 새로운 이미지를 생성하는 과정으로 이미지 변환의 한 형태이지만, CycleGAN과는 다르게 특정 이미지 간의 스타일을 전달하는 데 중점을 두고있음. CycleGAN은 전체 이미지 콜렉션의 스타일을 배우고, 이를 다른 도메인의 이미지에 적용 가능함.
짝이 없는 학습 데이터에서 동작 가능, cycle consistency를 통한 높은 품질의 이미지 변환은 CycleGAN의 차별점
3. Formulation
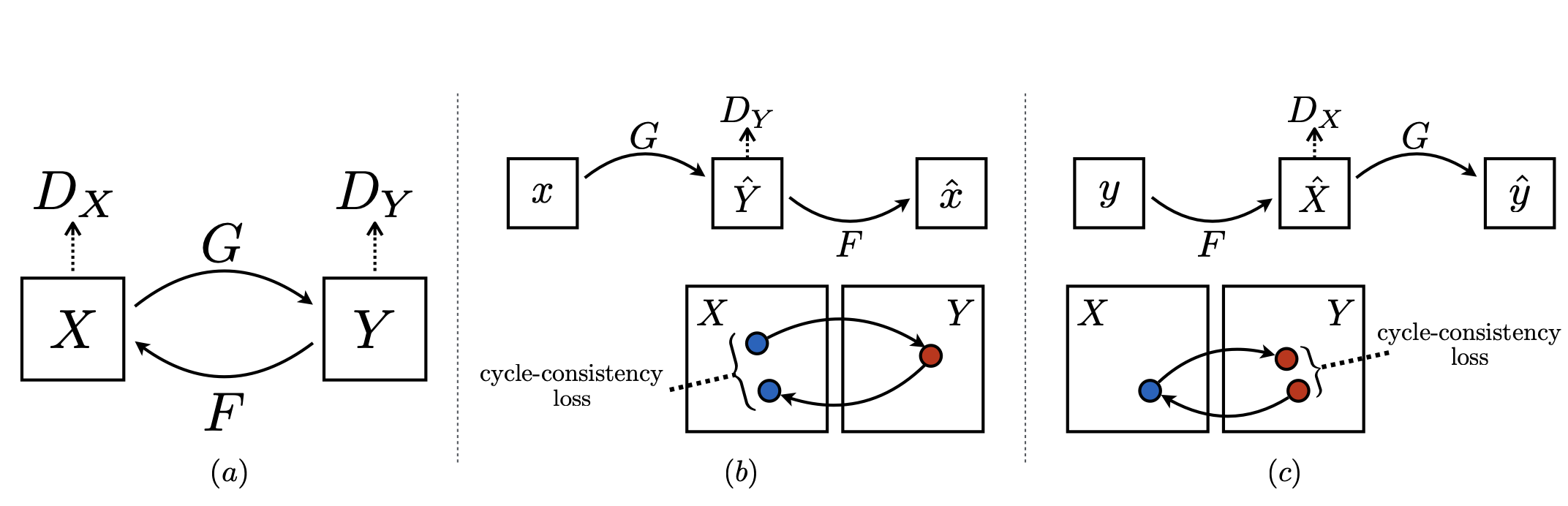
두 개의 GAN(Generative Adversarial Networks)을 사용하여 2개의 서로 다른 domain X, Y의 mapping을 학습하면 CycleGAN은 크게 2개의 mapping이 존재함.(G:X->Y, F:Y->X) 또한 2개의 Discriminator D(X), D(Y)를 두어서, D(X)는 x와 F(y)를 구분하고, D(Y)는 y와 G(x)를 구분함. Loss는 크게 adversarial loss(생성이미지와 target domain distribution matching)와 cycle consistency loss(학습된 G와 F가 서로 모순되는 것을 방지)로 구분함.
4. Results

사진과 지도 간 변환 작업에서 Amazon Mechanical Turk(AMT) 실험을 통해 CycleGAN이 생성한 이미지가 실제 이미지와 구분하기 어려운 정도로 높은 진짜 같음(realism)을 달성했다는 것을 확인함.

Cityscapes 데이터셋을 사용한 라벨에서 사진으로의 변환 작업에서 FCN 점수를 기반으로 한 평가에서도 CycleGAN이 기존 방법들보다 우수한 성능을 보임.
5. Limitations and Discussion

색상, 질감, 화풍 변환 작업에서는 cyclegan이 잘 적용되지만 기하학적 변화가 필요한 작업에서는 거의 성공하지 못한 한계를 가짐. dog→cat , apple→orange 예제에서 모양이 변하지 않는 것을 확인할 수 있음.
또 다른 한계는 훈련 데이터 세트의 분포 특성으로 인해 발생함. horse → zebra에서는 말이나 얼룩말을 타는 사람의 이미지를 포함하지 않는 ImageNet의 야생 말과 얼룩말 합성어 세트에 대해 훈련되었기 때문임
https://www.youtube.com/watch?v=Fkqf3dS9Cqw
저자의 강의라니!! 엄청 참고했습니다~
'AI' 카테고리의 다른 글
| Gemma sprint 후기 (0) | 2024.10.04 |
|---|---|
| [프롬프트] 생성형 AI 입문 완성강의 후기_(이론 및 기능 활용법) (0) | 2024.03.27 |
| Human-level Control Through Deep Reinforcement (1) | 2024.03.08 |
| Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2024.02.29 |
| Attention is All You Need (0) | 2024.02.22 |